
消息队列小专题
今天详细学习了一下消息队列的幂等性与重复消费问题,其实是在AI的模拟面试的时候被狠狠diss了 😥 😥
我在实习的时候,这一条链路的业务大致是这样的,我们拿到模型实例返回的计费数据和日志数据,我们要把他们持久化进Mongo中,持久化操作肯定还是异步比较舒服,而且我们肯定不能在本地直接开启那么多线程直接去异步调用Mongo,这样性能会被浪费,我实习的项目选择的是kafka进行业务解耦,通过consumer去调用Mongo,我们本地只需要发消息就行了。
那么使用消息队列就必须面对几个经典问题,如何保证消息不丢失,如何解决幂等性问题,怎样监控消息堆积量(吓哭了 😰 😰
我们先简单了解一下消息队列的组成和原理(以kafka为例):
要理解 Kafka,必须先掌握这几个核心概念:
- Producer (生产者): 往记事本上写数据的人(比如你的 MaaS 计费服务)。
- Consumer (消费者): 从记事本上读数据的人(比如你的 MongoDB 写入服务)。
- Broker (代理/服务器): 存放记事本的服务器节点。
- Topic (主题): 记事本的分类(比如“订单日志”、“用户日志”)。
- Partition (分区) —— *核心机制*:
- 为了存更多数据,Kafka 把一个 Topic 切分成多个 Partitions(分区)。
- 每个 Partition 是一个有序的队列,分布在不同的 Broker 上。
- 这是 Kafka 高并发的秘诀: 以前只能在一个本子上写,现在撕成 10 份,10 个人可以同时写!
其实我感觉消息队列都差不多,就是A如果想给C发消息,那A必须先把信给B,这个B跟邮局的作用差不多,把信件根据Topic归类整理,存档后分给订阅了这些消息的C,也就是收信人。
我们来了解一下具体的细节:
- 追加写:producer发送消息到broker,broker不是有分区吗,broker按照一定的规则将消息放到合适的partition,这个partition是一个物理概念,是一个磁盘的划分,新消息会追加写在旧消息的后面。
- offset:消息分区后还需要划分为多个segment,每个消息都有对应的offset,通过offset我们可以直接定位到这个消息的物理位置,直接获取该消息的内容
- 零拷贝:消息的读取直接使用系统缓存,不经过JVM虚拟机
简单了解消息队列后,我们来回答一下上面的发问:
怎么保证消息不丢失?
- 生产者:确保消息发出去。消息可能发出去但是broker没收到怎么办,我们可以通过消息回调,即broker收到消息后回发一个ack确认信息,生产者在确认ack后才能移动offset,否则超时重发
- broker:确保消息存下来。Broker 收到消息了,但还没来得及落盘(写入硬盘)就宕机了,或者内存满了。我们可以通过各消息队列的持久化机制解决这个问题
- 消费者:确保消息被处理。消息可能发出去但是消费者没收到,或者处理业务异常了怎么办,我们同样通过消息回调解决这个问题。
怎么保证不重复消费?
我们可以设置针对MessageID的去重表来解决这个问题,结合我实习的业务流程,他大致是这样的
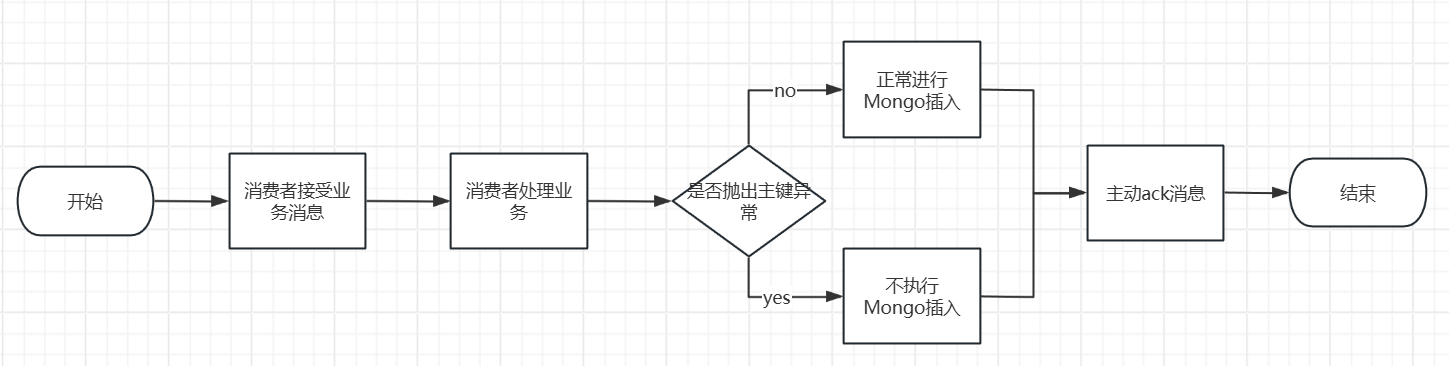
这里要注意的是:如果去重和业务处理是分开的,我们需要注意他们两的原子性。打个比方:
你的方案: “Consumer消费前,先插入 MessageID 到去重表。插入成功 -> 消费;插入失败 -> 跳过。”
场景推演(Bug 复现):
- Consumer 收到消息 A。
- 插入 MySQL 去重表成功(MessageID: A 已存在)。
- 【宕机时刻】:就在这一瞬间,Consumer 进程挂了,或者写入 MongoDB 超时了,或者业务逻辑报错了。总之,业务没跑完。
- 因为没有 ACK,Kafka 进行超时重发,再次投递消息 A。
- Consumer 重启,再次收到消息 A。
- 尝试插入 MySQL 去重表 -> 失败(因为第2步已经插进去了)。
- 你的逻辑判断:“插入失败 = 已经消费过”。于是你 ACK 并丢弃了这条消息。
结果: 数据库(MongoDB)里没有这条记录,但你的去重表说有。这条用户的计费记录永远丢失了。
怎么检查消息积压?
首先明确不应该检查内存使用情况,因为消息是持久化在硬盘中的。必须回答 Consumer Lag(消费积压量)。即 LogEndOffset (生产者写到了哪) 减去 CurrentOffset (消费者读到了哪)。
tk u ❤



